
「データサイエンスとAIの初歩」コースも台風の影響で一週間遅れでスタートしました。
Pythonの基礎的な文法から始め、組み込み関数であるrange関数の説明をしたところで早速、質問が出ました。
例えば
x = [i for i in range(10)]
print(x)
としてリストを作成し、表示してみましょう。
結果は
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
となります。
スタートポイントは0
エンドポイントは9で指定した10のひとつ前までです。
「なぜ、ひとつ前なのか?」
「仕様です」と言ってしまえば、おしまいですが、良い質問です。
まず、プログラムではスタートポイントが0というのはよくある話です。
コンピューターの中では0と1の2進数で処理が行われており、0から数えるというのは自然な流れかと思います。
(2進数の0は10進数でも0です。)
人間でも生まれたばかりの赤ちゃんは0歳児です。
なお、スタートポイントは変えることが出来ます。例えば
x = [i for i in range(1, 10)]
print(x)
とすると
[1, 2, 3, 4, 5, 6, 7, 8, 9]
となります。
(さらにステップを指定することもできます。)
それではなぜ指定したエンドポイントのひとつ前までなのか?
参考となる文献にダイクストラが書いたものがあります。
http://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html
ただし、これも必ずしも納得のいく説明とは限らないように思います。
x = [i for i in range(0, 10)]
を例にして考えてみましょう。
1.エンドポイントからスタートポイントを引くとリストの要素数になる。
10 – 0 = 10
これが要素数と一致すると言っています。
ただし、Pythonのlen関数を使えば要素数は簡単に得られますので、それほど強い理由ではないように思われます。
スタートポイントを省略した
range(10)
の場合は、確かに要素数が10個のリストを作成したいときにわかりやすいかもしれません。
2.空のリストを作るとき、醜い表現になる。
range(0, 0)
とすると空のリストになります。
もし、エンドポイントを含むとすると、
range(0, -1)
という醜い表現になるという訳です。
ただし、Pythonの場合は
x = []
で空のリストが作成できるので、これもあまり積極的な理由にはならないようにも思います。
3.隣接する2つの範囲(range)があるとき、一方のエンドポイントが他方のスタートポイントに等しいということも言っています。
例えば
範囲range(0, 10)を2つに分けるとき
range(0, 5)
range(5, 10)
となります。
ただし、自然数で考えているのでエンドポイントを含む場合でも
range(0, 5)
range(6, 10)
のようにすれば良いだけです。
実際、下で述べたように整数の乱数を発生するとき、標準ライブラリではエンドポイントを含みます。
ところが、実数の場合は、このことは重要です。
実数で範囲range(0, 10)を定義したとすると、
範囲range(0, 10)を2つに分けるにはエンドポイントを含まず
range(0, 5)
range(5, 10)
とするのが妥当です。
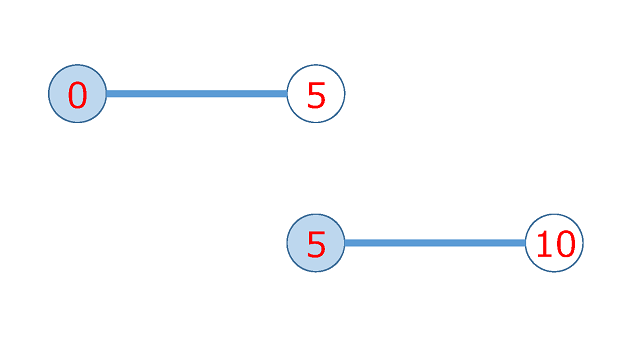
rangeがエンドポイントを含むとすると
range(0, 5)
と
range(5, 10)
の両方に5が含まれてしまい数学的におかしなことになってしまいます。
このことから、範囲を指定して実数の乱数を発生するときにも、エンドポイントは含みません。
このような連続した実数の場合の類推から整数やとびとびの実数を扱うrange関数においてもエンドポイントは含まない方が素直な考えのように思われます。
なお、ダイクストラはスタートポイントを含む理由についても触れています。
range(0, 10)は
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
というリストを表現できますが、もしスタートポイントを含まないとすると
range(-1, 10)
という記述になります。
これはカッコ悪いという訳です。
関連した話題として、整数の乱数が欲しいときに、標準ライブラリのrandomを使用するか、外部ライブラリのnumpyを使用するかで状況が異なるということがあります。
標準ライブラリのrandomを使用した場合は、
import random
x = random.randint(1, 3)
print(x)
とすると
エンドポイント3を含んだ乱数が得られます。
上記の流れから言うと、ひとつ前の2までの乱数であって欲しいのですが。
外部ライブラリのnumpyを使用した場合は、
import numpy as np
x = np.random.randint(1, 3)
print(x)
とすると
エンドポイントのひとつ前の2までの乱数が得られます。こちらの方が自然な考え方のように思います。
注意が必要ですね。

