
■今回の内容
前回の感染症のシミュレーション2ではSIRモデルによるシミュレーションを行いました。
今回は新型コロナウイルス感染症について報告されているデータとシミュレーション結果との比較を行ってみます。
さらに後半では報告されている各国のデータのビジュアライゼーションを行ってみます。
■背景
新型コロナウイルス感染症については、メディアによる様々な報道がなされていますが、データに基づかないものも多く見受けられます。
当プログラミング教室で重要視しているクリティカルシンキング(聞いたことを鵜呑みにしない。自分で確かめる。)がこのようなときにも基本です。
各種データは公開されていますので、自分でデータを分析して科学的に情勢を見極める姿勢が大事です。
当プログラミング教室の「データサイエンスとAIの初歩」コースはそのような力をつけるためにやっています。
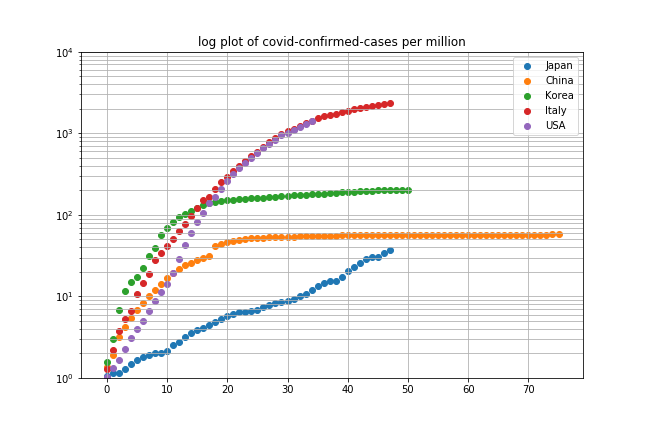
■SIRモデルによるシミュレーション結果と東京都の累積感染者数との比較
「感染症のシミュレーション2」と同じ手法でパラメータを調整しました。
具体的には実効再生産数を1.56としました。
また、縦軸をリニアスケールから対数スケールにしました。リニアスケールでは目盛が1, 2, 3と増えていきますが、対数スケールでは1, 10, 100と増えていきます。
この対数スケールは指数関数的に急激に増加するデータを図示するのに向いています。感染者数が少ない頃のデータもよくわかります。この片側対数プロットでは変化が直線的なとき、実際には指数関数的に変化していることを意味します。
結果は下図のようになりました。
実線は単純なSIRモデルにより得られた曲線です。単純なモデルですので予測と言えるほどのものではなく参考程度に考えておいた方が良いでしょう。
青丸が東京都の累積感染者数です。4月10日までのデータを用いています。
ほぼ、指数関数的に伸びていることがわかります。
橙色の丸は、専門家委員会から報告されている対策をしなかった場合の予測値で、2週間後に1万人、30日後に8万人です。
■各国の累積感染者数のビジュアライゼーション
感染者数などのデータは

にまとめられているものを利用させて頂きました。4月10日現在のデータを用いました。
このサイトにもグラフがたくさんありますが、必要なデータだけをPythonのプログラムで抜き出しプロットしました。
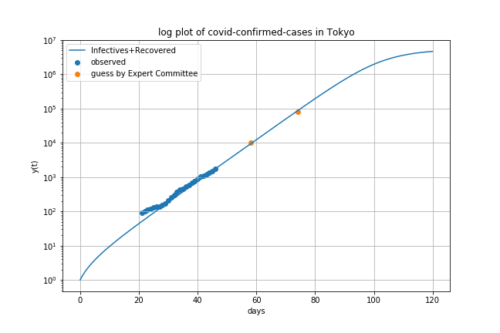
まず、人口100万人当たりの累積感染者数をプロットしてみます。縦軸は対数スケールです。
日本は青丸で表示しています。
傾きは緩やかですが、着実に指数関数的に伸びていく傾向が見られます。
橙色は中国ですが、ほぼ飽和しており累積感染者数は横ばいです。
日本はこの中国を追い越しそうな様相を呈しています。
緑は韓国です。こちらも中国同様、飽和気味ですが、まだ少し増加傾向にあります。
アメリカ、イタリアはよく似た曲線です。人口当たりの感染者数は非常に多いですが、ようやく飽和傾向が見られるようになってきました。
次に感染者数そのものでプロットしてみます。人口に対する比率を考慮しない実数です。
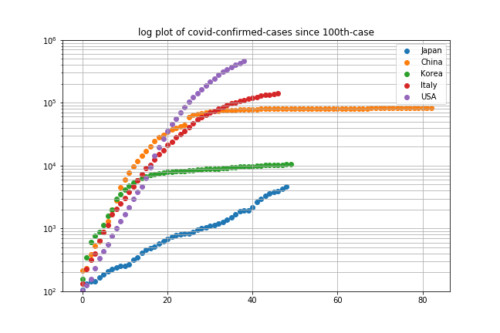
青丸の日本は緑丸の韓国の感染者数を追い抜きそうな勢いです。
何もしなければ、このまま指数関数的に伸びていきます。
徹底した個人の自覚と良識に基づく冷静な行動が必要であり、企業においては、その社会的責任と使命を果たす決意が必要です。
Stay Home! Stay Home! Stay Home!

